BookMark’d saves links and is your own personal search engine.
Or at least that’s the work in progress tag line.
I was sitting at my computer this weekend and remembered that I bookmarked an interesting page. I was trying to find the bookmark, but I couldn’t. I even tried the bookmark search tool, but that only matches if a word or phrase is in a page, so I could be stuck with a lot of results, or have the wrong word and not get the result I need.
Of course, I’ve tried to organize my bookmarks into folders, but then if I wanted something in multiple folders. I’d have to bookmark it twice. And the whole interface for adding bookmarks into folders is a pain. Of course there’s always delicious, but that only lets me search through tags, and who really remembers all of that?
So I decided to crank out my own solution that works the way I want (hopefully someday, it’s still in development). You can see a live example at markd.6km.me.
Introducing BookMark’d
BookMark’d is my solution to the bookmarking problem. You can contribute to the code and scoff at it on Github. The idea is kind of similar to Mahalo, but you’re the one curating the content.
BookMark’d gives you a bookmarklet to post sites to your installation. It will then read the page and store it in it’s database. When you want to find a specific page, just search.
But why should you use BookMark’d (someday, not yet)?
A Contrived Example
In my browser, I have several bookmarks on PHP and cURL. If I wanted to find information on PHP and cURL, I can tell my browser to give me the results of my bookmarks that contain those terms. With BookMark’d, it tries to find documents that mean what I’m searching for. So let’s say I search for ‘php curl’.
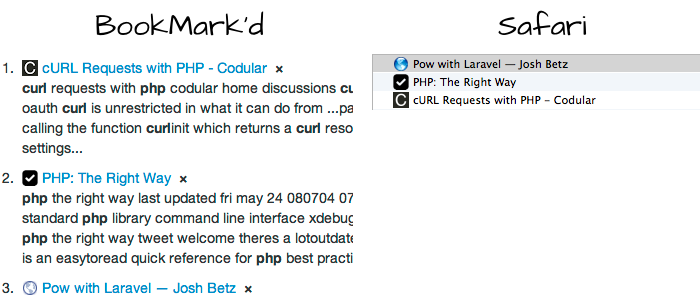
We can see that BookMark’d returns a result on how to write a cURL request with PHP at the top. Safari returns Pow with Larvel and PHP The Right Way before that. If you look at these documents, they do contain the terms php and curl, but they’re for installation scripts, and not what the document really means. Of course, BookMark’d returns all documents that contain those terms, but it tries to return them by meaning, as we add more features, hopefully we can narrow down the results.
Why use BookMark’d? (someday)
Because you love me? Just kidding. Personally, I like keeping my browser nice and clean. I also like the idea of what I find interesting not being tied to a specific browser or computer. So saving bookmarks “to the cloud” seems ideal for me.
I also wanted to be able to search through my bookmarks by meaning. I don’t mean definition wise, but knowing that when I search ‘github pages’, I get links where the content is relevant to those terms, not just containing them. If I search for ‘documents’, I don’t get results for ‘pages’ even though they could mean the same thing.
So other than managing bookmarks and creating your own mini-search engine, what else could you use BookMark’d for?
Personalized Search
Most sites currently use Google or Bing to perform a site specific search for their search results. This is okay at times, but not always. For instance, I wrote a post on switching to outlook. It’s about a Microsoft product. So if we do a site specific search on Bing or Google, my post is very low ranked or doesn’t show up at all (as of writing). That’s because I need to wait for them to index my site. Even if they do index my site, their ranking method might not prefer newer pages. If we look at how BookMark’d performed, we can see the post is higher ranked compared to posts on my site that have nothing to do with Microsoft (as of writing1). Also, users can search pages that actually contain content instead of seeing results that include my archives and category pages.
Of course, BookMark’d doesn’t perform more advanced searching features yet. I could setup a robots.txt file and use Google or Bing, but that would be no fun. BookMark’d also doesn’t crawl pages, but this use wasn’t it’s original purpose.
But now, if you use the search bar on this site, it will direct you to search.6km.me. So all of the results will be specific to the content on this site.
Technical Stuff?
So what is BookMark’d currently missing?
- Recaching of Pages
- Content on pages changes, BookMark’d doesn’t keep up.
- Content only
- Websites contain side bars, headers, footers, and more. BookMark’d currently uses all of that data in the search instead of just the page content. For example if you search for ‘microsoft’, a lot of pages show up because ‘microsoft’ is in the side bar.
- Tagging
- A feature that will hopefully come sooner than later, hopefully along with auto-tagging.
- Improved search algorithm and capabilities
- BookMark’d currently only performs an inclusive “OR” search on words. It doesn’t take into account phrases or spacing on a page.
- Character Encodings
- BookMark’d only works for American English (I want to say?). It can’t handle foreign or special characters.
How does BookMark’d work?
I think it’s kind of cool, but this is a really basic idea compared to some of the other things out there. BookMark’d extracts the terms from all the web pages you send to it. It then stores the terms and the number of times it appears on each web page into the database.
When you perform a search, it calculates a modified TF-IDF vector based on your search terms. The term frequency is how often a word appears in the web page. We then divide the term frequency of the word your interested in over the largest term frequency of any term on the page. If the value is close to 1, the term is prevalent in that document (not necessarily to that document though like the words ‘a’, ‘and’, and ‘the’). In order to see if the word has meaning to the document, we calculate the inverse document frequency, which is the log of the total number of documents pages divided by the number of pages that contain the search term. If this value is large, then the word is used in a fewer number of pages meaning it is a more important term in differentiating between pages.
So we take the Term Frequency (per page) and the Inverse Document Frequency (constant for each term), and multiply them. Pages with a larger TF-IDF for that term mean that the term has more meaning on that page (or is more important to)2. We take the TF-IDF values for each term and each page and sum them together. Which ever result has the largest sum is considered to be the most relevant to the search query3.
 Of course, we do some other things as well. We penalize pages that don’t contain a search term. We also try to weight in popularity. You can view the code here.
Of course, we do some other things as well. We penalize pages that don’t contain a search term. We also try to weight in popularity. You can view the code here.
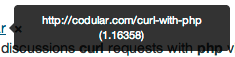
You can see the score for each page when you perform a search by hovering over a link. The score in in the parentheses4.
Other (more mature) software
Thanks for reading!
-
BookMark’d ranks pages based on content and interest. Right now, search.6km.me hasn’t been used much, so my BookMark’d installation doesn’t know how to rank pages based on interest. Of course, I’m not sure if the way we weight interest is ideal yet. ↩
-
People abuse this fact which is why you’ll see pages filled with the same search term over and over to boost their result. ↩
-
For single word queries, the page with the highest term frequency is returned first. With multi-worded queries, you get more meaningful results. ↩
-
This number is pretty useless on it’s own. If you compare them on a single page, it helps to show how well the search algorithm is on identifying meaningful pages for that query. There’s usually a point where you can see a significant gap in scores, kind of cool, right? ↩