Cortana, Alexa, Siri, and then some. Digital assistants are invading our lives, and I’m loving every minute of it.
As a kid I loved Digimon. I thought it would be cool to get sucked into the internet and hang out with my digital partner. It’s pretty much the reason I got into computers. I started poking around at computer vision and machine learning in hopes of one day getting sucked into the internet making computer interaction more natural.
Some people have been working on the problem a lot longer than me, but I thought it’d be fun to share some approaches on the subject. This is part one… There’s a lot of content to cover.
For our first approach, we’re going to break the problem down into 3 layers:
- Tokenization
- Classification
- Extraction
The rest of the code referenced in this post can be found in the Acme::Skynet repository.
Tokenization is the process of breaking down text into sentences, words, or phrases. This will allow us to look at each part of the command or phrase.
Classification is determining what action the phrase wants. If you ask your digital assistant “Remind me in 10 minutes to take the chicken out of the oven” The brain of the digital assistant might classify this as a timer or reminder problem.
Extraction is retrieving the context of the problem. “Remind me in 10 minutes to take the chicken out of the oven” can be classified as a reminder problem. When do we want the reminder? In 10 minutes. What is the reminder? To take the chicken out of the oven. This process of determining our arguments is what we’re calling Extraction for today.
Battle Plan
For Tokenization, we’re only going to handle a single sentence. We’re stripping most punctuation, and breaking it down into words and pairs of words.
For Classification, we’re going to use an ID3 tree. The input will be a phrase and output the type of problem.
remind me in 10 minutes to remove the chicken from the oven -> reminder
For Extraction, we’re going to use a training set to generate a state diagram. Certain states will be our arguments, where other states determine where we are in the command (more explained later).
Tokenization
For tokenization, we want to break a text into manageable bits. For our problem, we’re only looking at a single sentence. In order for us to handle multiple forms of the same root word, we’ll use a Stemmer. Luckily, in Perl 6, someone has already written an implementation of the Porter stemmer we can use.
In order to handle varying text, we also want to expand contractions before stemming. The code for expanding contractions looks something like:
sub decontract(Str $word)
{
my $result = $word;
$result ~~ s:g/can\'t/cannot/;
$result ~~ s:g/won\'t/will not/;
$result ~~ s:g/n\'t/ not/;
$result ~~ s:g/\'re/ are/;
$result ~~ s:g/\'ll/ will/;
$result ~~ s:g/\'ve/ have/;
$result ~~ s:g/\'d/ would/;
$result ~~ s:g/\'s/ is/;
$result ~~ s:g/o\'clock/of the clock/;
return $result;
}
What we wind up doing is passing each word in the sentence into our decontract subroutine, and then pass each resulting word through the porter stemmer, keeping each word in a list. You can see this in the Acme::Skynet::DumbDown module.
Classification
For classification, we’re going to look at generating an ID3 tree. ID3 is a really cool because it’s based off of grouping tasks by entropy.
The central idea is similar to sorting laundry. As you go, you ask yourself ‘Is it light or dark?’, ‘Pants or shirt?’, ‘Normal or Gentle wash?’, then you throw it into the corresponding pile.
When you start with all of your dirty clothes, you might kick them into 2 piles, then separate the bigger piles into smaller ones. This is pretty similar to the ID3 algorithm. Our implementation can be seen at Acme::Skynet::ID3.
Entropy is defined as:
\[H(S) = - \sum_{x \in X} p(x) log_2 p(x)\]where \(S\) is the set of data, \(X\) are the labels, and \(p(x)\) is the number of data items with label \(x\) over all data items.
Information Gain is calculated by looking at knowledge we gain by breaking on a feature. Each data item has features or attributes \(A\). In our laundry example, color (light or dark) would be an feature of the data. If attribute \(A\) splits our set \(S\), the calculation looks like:
\[IG(A, S) = H(S) - \sum_{t \in T} p(t)H(t)\]where \(T\) are the subsets created by splitting on the attribute (if color, there would be 2 subsets, one for light, and one for dark). \(p(t)\) is the number of items that would be placed in that set over the number of items currently in \(S\).
The whole code can be seen in the information gain and learn methods in ID3.pm6. We look at all of the options, and select the one with the max gain.
my $possibleEntropy = %options.values.map(-> $possibleKid {
$possibleKid.entropy() * ($possibleKid.elems() / self.elems())
}).reduce(*+*);
my $infoGain = $entropy - $possibleEntropy;
if ($infoGain > $maxGain) {
%!children = %options;
$!feature = $feature;
$maxGain = $infoGain;
}
We continue this process until all items in our data set \(S\) have the same label, or until we run out of features to split on. If you run down a path of the tree, you should not see the same feature more than once.
For our text, features are the words in our training set. The values for the features are either True word is present, or False word is not present.
When we have a new command, we can go down our tree and see if the command contains the key words. If we stop part way, we select the label with the highest probability. If we make it to a leaf on the tree, we take the label of the leaf.
This guessed label will tell us what we should try to extract from the command.
Extraction
For basic extraction, we created a graph of our tokenized strings for each class. The graph shows connections between the tokens and arguments. This is a basic method that does a single pass through on the newly observed data. There’s no backtracking. This can cause problems with certain ‘cue’ words appearing multiple times throughout an observation. You can see a full implementation at Acme::Skynet::ChainLabel.
For the graph generation, we used
# Generate a graph based on the phrases
%!nodes{'.'} = Node.new();
# simpleCommands contains a list of training data, where
# each command looks something like:
#
# remind me to ARG:0 at ARG:1
#
for @simpleCommands -> $command {
# '.' symbolizes the start of a command
my $previousWord = '.';
# We split the command up into each token.
for $command.split(/\s+/) -> $word {
%!nodes{$word} = Node.new();
# we see if we have a connection between the current token
# and the next one. If not, add one.
unless (self.pathExists($previousWord, $word)) {
%!paths.push: ($previousWord => $word);
}
$previousWord = $word;
}
}
This code generates a map that represents our graph. For example, if we had
remind me to ARG:0 at ARG:1remind me at ARG:1 to ARG:0
We’d have a table like:
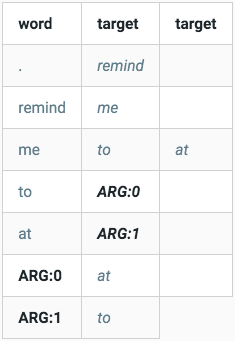
so when we traverse a new sentence, if we see the word “to”, we know that the next word probably goes into ARG:0, and the words stay there until the end of the string, or until we reach a “at”. remind me to eat pizza at lunch, if we follow our table would place eat pizza in ARG:0, and lunch in ARG:1.
In the actual code, we tokenize the unseen command and keep both the original and the simplified version. As we traverse the simplified version, we store the corresponding original part in our ARG:* nodes.
Once we reach the end of the string, we dump the contents of our ARG:* nodes.
Determining Intent (or putting it all together)
We called our implementation Skynet.
The classifier is trained on all of the data. We have only 1 classifier.
We need an extractor for every possible action. In our example, 1 for time, 1 for reminders, and 1 for stabbing… The data points for time should not be used to train the reminders extractor.
method add(&route, Str $sentence, *@arguments) {
# Route: Function to call
# Sentence: String command
# Arguments: Arguments to extract from command
my $train = DataPoint.new(&route, $sentence, @arguments);
# Create the ID3Tree
unless ($!built) {
$!built = True;
$!classifier = ID3Tree.new();
}
# Add data point to classifier
$!classifier.addItem($train);
# Create a labeller for this route if needed
unless (%!labelers{&route.gist()}:exists) {
%!labelers{&route.gist()} = ChainLabel.new();
}
# Add data point to labeller
%!labelers{&route.gist()}.add($train.command, $train.args);
}
method learn() {
# Train the classifier
$!classifier.learn();
# Train the labelers
for %!labelers.values -> $labeller {
$labeller.learn();
}
}
method hears(Str $whisper) {
# Create a new command with no known route
my $command = DataPoint.new($emptySub, $whisper);
# Classify the command
my $action = $!classifier.get($command);
# Get the arguments.
my @args = %!labelers{$action}.get($command.command);
my &route = %!router{$action};
# Run the corresponding command
route(@args);
}
Conclusions…?
I hope this peaked your interest in determining intent. This is a very basic implementation, and there’s a lot of research going on in this area. Feel free to comment below or tweet at me for more info.
Next time will look at backtracking or multiple iterations for our Extraction step.